Seurat standard pipeline
记录一下Seurat标准的单细胞分析流程,这里使用官方提供的pbmc3k作为示例
pbmc3k: https://cf.10xgenomics.com/samples/cell/pbmc3k/pbmc3k_filtered_gene_bc_matrices.tar.gz
Seurat单细胞分析流程主要就是以下十句代码
1 | pbmc.counts <- Read10X(data.dir = "data/filtered_gene_bc_matrices/hg19/") |
以下详细展开某一步的功能
1 | library(dplyr) |
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
1 | library(Seurat) |
## Attaching SeuratObject
1 | library(patchwork) |
创建Seurat对象
Seurat接受counts文件作为输入(一般经过cellranger处理),创建包含细胞信息和counts信息的对象。
1 | # Load the PBMC dataset |
## Warning: Feature names cannot have underscores ('_'), replacing with dashes
## ('-')
1 | pbmc |
## An object of class Seurat
## 13714 features across 2700 samples within 1 assay
## Active assay: RNA (13714 features, 0 variable features)
Seurat对象中的counts以稀疏矩阵的方式存储以节省内存,. 表示没有检测到counts
1 | # Lets examine a few genes in the first thirty cells |
## 3 x 10 sparse Matrix of class "dgCMatrix"
## [[ suppressing 10 column names 'AAACATACAACCAC-1', 'AAACATTGAGCTAC-1', 'AAACATTGATCAGC-1' ... ]]
##
## CD3D 4 . 10 . . 1 2 3 1 .
## TCL1A . . . . . . . . 1 .
## MS4A1 . 6 . . . . . . 1 1
质控
一般而言,我们需要对数据进行质控以保证数据的质量,在进行后续的分析。常用的质控指标包括:
每个细胞的唯一基因数目
低质量或空液泡往往只能检测到少量基因
双液泡(doublet)或多液泡(multiplets)会具有异常多的基因数目
每个细胞的总counts数(相当于每个细胞的测序深度)
线粒体基因占比
- 低质量或死细胞会具有异常高的线粒体基因表达
由于每个细胞的基因数和测序深度在cellranger分析的时候已经计算过了,这里我们只需要再计算线粒体基因表达的比例即可
1 | # The [[ operator can add columns to object metadata. This is a great place to stash QC stats |
Seurat将细胞相关的元数据以列的形式存储在 pbmc@meta.data
1 | # Show QC metrics for the first 5 cells |
## orig.ident nCount_RNA nFeature_RNA percent.mt
## AAACATACAACCAC-1 pbmc3k 2419 779 3.0177759
## AAACATTGAGCTAC-1 pbmc3k 4903 1352 3.7935958
## AAACATTGATCAGC-1 pbmc3k 3147 1129 0.8897363
## AAACCGTGCTTCCG-1 pbmc3k 2639 960 1.7430845
## AAACCGTGTATGCG-1 pbmc3k 980 521 1.2244898
1 | # Visualize QC metrics as a violin plot |
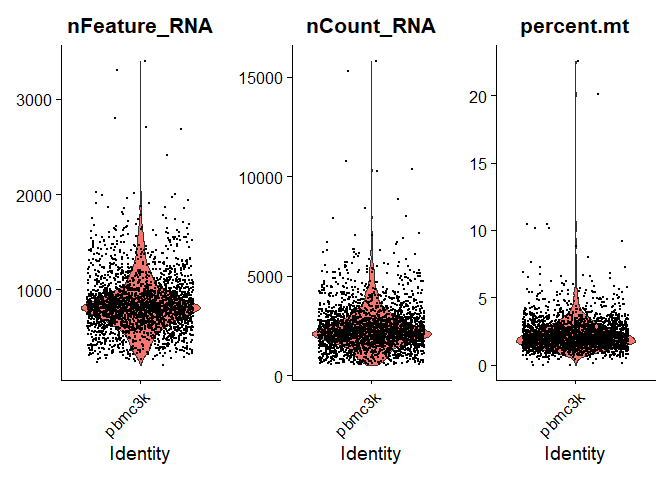
随后,我们过滤掉基因数(nFeature_RNA)大于2500或小于200的细胞,以及线粒体基因组比例大于5%的细胞
1 | pbmc <- subset(pbmc, subset = nFeature_RNA > 200 & nFeature_RNA < 2500 & percent.mt < 5) |
需要注意的是这里的过滤标准在适合在这个数据集中使用,未必适用于其他的数据集。更好的质控方法是根据质控指标的分位数进行过滤,例如过滤掉 nFeature_RNA 上四分位数和下四分位数的细胞。
另外,这里只使用了三种指标对细胞进行质控,在实际分析中我们还可以使用其他工具进行更精密的质控,例如:
- SoupX removes ambient RNA contamination from droplet-based single-cell RNA sequencing data (https://github.com/constantAmateur/SoupX)
- DoubletFinder: Doublet Detection in Single-Cell RNA Sequencing Data Using Artificial Nearest Neighbors (https://github.com/chris-mcginnis-ucsf/DoubletFinder)
- DropletQC: improved identification of empty droplets and damaged cells in single-cell RNA-seq data (https://github.com/powellgenomicslab/DropletQC)
Normalization
在质控后,我们进行counts的normalization,默认使用 “LogNormalize” 的方法,即将每个基因的counts除以细胞总的counts数,乘上10,000,再进行对数转换。
1 | pbmc <- NormalizeData(pbmc) |
Seurat提供了另外的normalization方法,通过
normalization.method指定, 包括:
“CLR”: centered log ratio transformation
“RC”: equals to “LogNormalize” without log-transformation
校正后的数据在 pbmc[["RNA"]]@data
1 | pbmc[["RNA"]]@data[c("CD3D", "TCL1A", "MS4A1"), 1:10] |
## 3 x 10 sparse Matrix of class "dgCMatrix"
## [[ suppressing 10 column names 'AAACATACAACCAC-1', 'AAACATTGAGCTAC-1', 'AAACATTGATCAGC-1' ... ]]
##
## CD3D 2.864242 . 3.489706 . . 1.726902 2.321937 2.658463 2.179642
## TCL1A . . . . . . . . 2.179642
## MS4A1 . 2.583047 . . . . . . 2.179642
##
## CD3D .
## TCL1A .
## MS4A1 2.309182
特征选择
Seurat选择在细胞细胞之间具有高度变异性的基因(例如某些细胞高表达,而其他细胞不表达)进行后续分析,这是由于这些基因可以代表了细胞与细胞间的主要生物学差异
1 | pbmc <- FindVariableFeatures(pbmc, selection.method = "vst", nfeatures = 2000) |
## When using repel, set xnudge and ynudge to 0 for optimal results
1 | plot1 + plot2 |
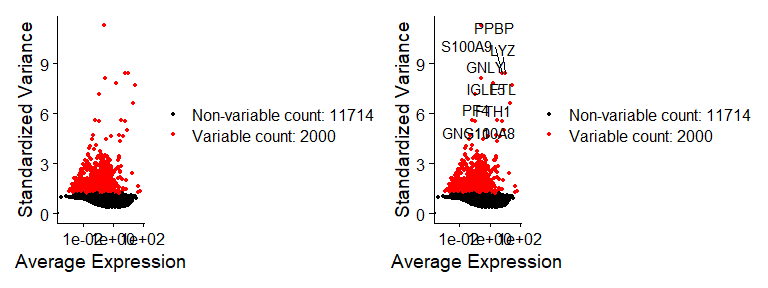
默认选择前2000个高度变异基因。
数据缩放
Normalization后,需要对数据进行缩放(Scaling)。 Scaling后,数据的均值为0,方差为1
1 | all.genes <- rownames(pbmc) |
## Centering and scaling data matrix
scaled data存放在 pbmc[["RNA"]]@scale.data
1 | pbmc[["RNA"]]@scale.data[c("CD3D", "TCL1A", "MS4A1"), 1:10] |
## AAACATACAACCAC-1 AAACATTGAGCTAC-1 AAACATTGATCAGC-1 AAACCGTGCTTCCG-1
## CD3D 1.2509633 -0.9797929 1.7380926 -0.9797929
## TCL1A -0.3187677 -0.3187677 -0.3187677 -0.3187677
## MS4A1 -0.4110536 2.5965712 -0.4110536 -0.4110536
## AAACCGTGTATGCG-1 AAACGCACTGGTAC-1 AAACGCTGACCAGT-1 AAACGCTGGTTCTT-1
## CD3D -0.9797929 0.3651696 0.8286000 1.0906967
## TCL1A -0.3187677 -0.3187677 -0.3187677 -0.3187677
## MS4A1 -0.4110536 -0.4110536 -0.4110536 -0.4110536
## AAACGCTGTAGCCA-1 AAACGCTGTTTCTG-1
## CD3D 0.7177763 -0.9797929
## TCL1A 2.3330706 -0.3187677
## MS4A1 2.1268583 2.2776908
线性降维
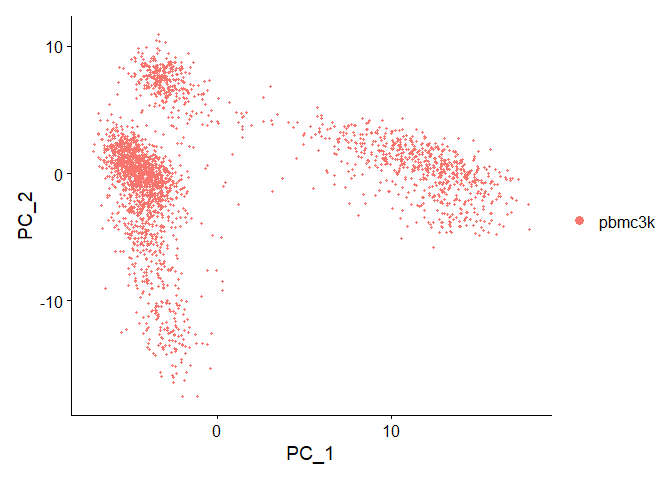
Seurat 使用PCA进行降维,这里只对 FindVariableFeatures 挑选出的高变基因进行PCA分析
1 | pbmc <- RunPCA(pbmc, features = VariableFeatures(object = pbmc)) |
## PC_ 1
## Positive: CST3, TYROBP, LST1, AIF1, FTL, FTH1, LYZ, FCN1, S100A9, TYMP
## FCER1G, CFD, LGALS1, S100A8, CTSS, LGALS2, SERPINA1, IFITM3, SPI1, CFP
## PSAP, IFI30, SAT1, COTL1, S100A11, NPC2, GRN, LGALS3, GSTP1, PYCARD
## Negative: MALAT1, LTB, IL32, IL7R, CD2, B2M, ACAP1, CD27, STK17A, CTSW
## CD247, GIMAP5, AQP3, CCL5, SELL, TRAF3IP3, GZMA, MAL, CST7, ITM2A
## MYC, GIMAP7, HOPX, BEX2, LDLRAP1, GZMK, ETS1, ZAP70, TNFAIP8, RIC3
## PC_ 2
## Positive: CD79A, MS4A1, TCL1A, HLA-DQA1, HLA-DQB1, HLA-DRA, LINC00926, CD79B, HLA-DRB1, CD74
## HLA-DMA, HLA-DPB1, HLA-DQA2, CD37, HLA-DRB5, HLA-DMB, HLA-DPA1, FCRLA, HVCN1, LTB
## BLNK, P2RX5, IGLL5, IRF8, SWAP70, ARHGAP24, FCGR2B, SMIM14, PPP1R14A, C16orf74
## Negative: NKG7, PRF1, CST7, GZMB, GZMA, FGFBP2, CTSW, GNLY, B2M, SPON2
## CCL4, GZMH, FCGR3A, CCL5, CD247, XCL2, CLIC3, AKR1C3, SRGN, HOPX
## TTC38, APMAP, CTSC, S100A4, IGFBP7, ANXA1, ID2, IL32, XCL1, RHOC
## PC_ 3
## Positive: HLA-DQA1, CD79A, CD79B, HLA-DQB1, HLA-DPB1, HLA-DPA1, CD74, MS4A1, HLA-DRB1, HLA-DRA
## HLA-DRB5, HLA-DQA2, TCL1A, LINC00926, HLA-DMB, HLA-DMA, CD37, HVCN1, FCRLA, IRF8
## PLAC8, BLNK, MALAT1, SMIM14, PLD4, LAT2, IGLL5, P2RX5, SWAP70, FCGR2B
## Negative: PPBP, PF4, SDPR, SPARC, GNG11, NRGN, GP9, RGS18, TUBB1, CLU
## HIST1H2AC, AP001189.4, ITGA2B, CD9, TMEM40, PTCRA, CA2, ACRBP, MMD, TREML1
## NGFRAP1, F13A1, SEPT5, RUFY1, TSC22D1, MPP1, CMTM5, RP11-367G6.3, MYL9, GP1BA
## PC_ 4
## Positive: HLA-DQA1, CD79B, CD79A, MS4A1, HLA-DQB1, CD74, HLA-DPB1, HIST1H2AC, PF4, TCL1A
## SDPR, HLA-DPA1, HLA-DRB1, HLA-DQA2, HLA-DRA, PPBP, LINC00926, GNG11, HLA-DRB5, SPARC
## GP9, AP001189.4, CA2, PTCRA, CD9, NRGN, RGS18, GZMB, CLU, TUBB1
## Negative: VIM, IL7R, S100A6, IL32, S100A8, S100A4, GIMAP7, S100A10, S100A9, MAL
## AQP3, CD2, CD14, FYB, LGALS2, GIMAP4, ANXA1, CD27, FCN1, RBP7
## LYZ, S100A11, GIMAP5, MS4A6A, S100A12, FOLR3, TRABD2A, AIF1, IL8, IFI6
## PC_ 5
## Positive: GZMB, NKG7, S100A8, FGFBP2, GNLY, CCL4, CST7, PRF1, GZMA, SPON2
## GZMH, S100A9, LGALS2, CCL3, CTSW, XCL2, CD14, CLIC3, S100A12, CCL5
## RBP7, MS4A6A, GSTP1, FOLR3, IGFBP7, TYROBP, TTC38, AKR1C3, XCL1, HOPX
## Negative: LTB, IL7R, CKB, VIM, MS4A7, AQP3, CYTIP, RP11-290F20.3, SIGLEC10, HMOX1
## PTGES3, LILRB2, MAL, CD27, HN1, CD2, GDI2, ANXA5, CORO1B, TUBA1B
## FAM110A, ATP1A1, TRADD, PPA1, CCDC109B, ABRACL, CTD-2006K23.1, WARS, VMO1, FYB
1 | DimPlot(pbmc, reduction = "pca") |
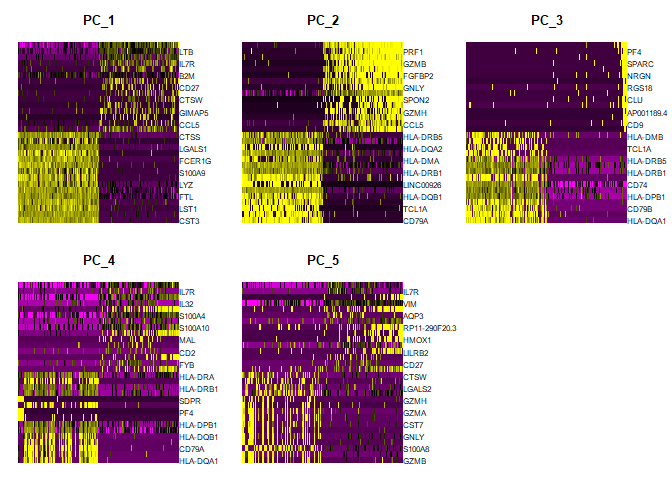
1 | DimHeatmap(pbmc, dims = 1:5, cells = 500, balanced = TRUE) |
维数选择
Seurat在主成分PC上进行聚类。然而直接对所有PC聚类是不现实的,我们需要选择足够的PC以代表数据的主要变异度,同时控制计算资源的开销。
因此,Seurat结合JackStraw程序和置换检验对PC进行显著性分析,鉴定出显著的PC以进行后续分析。
1 | # NOTE: This process can take a long time for big datasets, comment out for expediency. More |
PC11之后,PC的p-value就发生了迅速的上升,而变得不显著。
1 | JackStrawPlot(pbmc, dims = 1:15) |
## Warning: Removed 23496 rows containing missing values (geom_point).
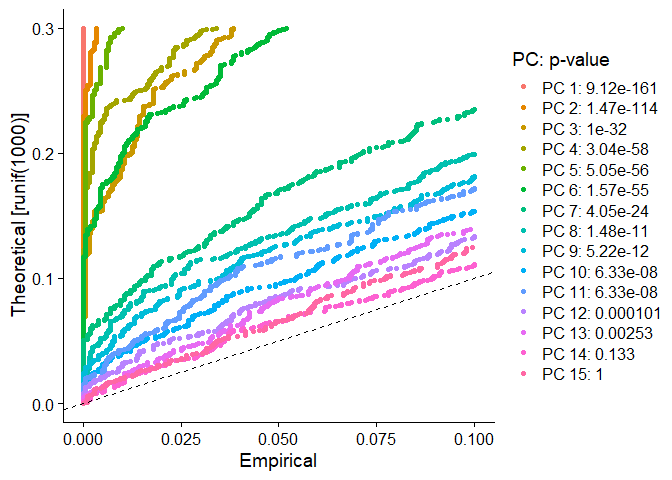
我们还可以结合elbow plot进行判断,选择拐点和曲线平滑的PC
1 | ElbowPlot(pbmc) |
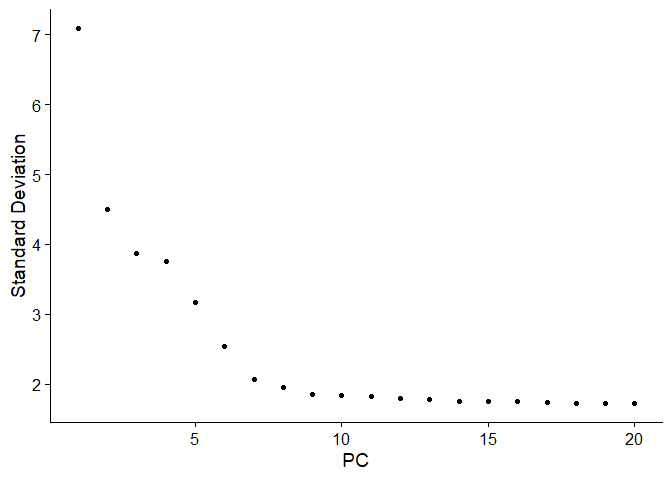
综上,我们选取前10个维度进行后续分析
细胞聚类
Seurat使用基于图的聚类算法对细胞进行聚类
FindNeighbors 中的 dims 参数指定聚类使用的维度
FindClusters 中的 resolution 参数指定类别的精度,越大则分出越多的类;越小则类别越少
1 | pbmc <- FindNeighbors(pbmc, dims = 1:10) |
## Computing nearest neighbor graph
## Computing SNN
1 | pbmc <- FindClusters(pbmc, resolution = 0.5) |
## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck
##
## Number of nodes: 2638
## Number of edges: 95965
##
## Running Louvain algorithm...
## Maximum modularity in 10 random starts: 0.8723
## Number of communities: 9
## Elapsed time: 0 seconds
1 | table(Idents(pbmc)) |
##
## 0 1 2 3 4 5 6 7 8
## 711 480 472 344 279 162 144 32 14
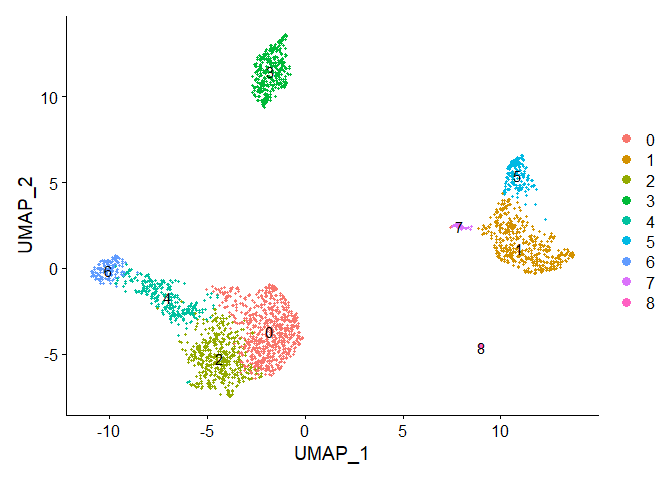
非线性降维(UMAP/tSNE)
非线性降维捕捉数据内部的流式(manifold)以将细胞投射到低维空间中。
1 | # If you haven't installed UMAP, you can do so via reticulate::py_install(packages = |
## Warning: The default method for RunUMAP has changed from calling Python UMAP via reticulate to the R-native UWOT using the cosine metric
## To use Python UMAP via reticulate, set umap.method to 'umap-learn' and metric to 'correlation'
## This message will be shown once per session
## 22:52:48 UMAP embedding parameters a = 0.9922 b = 1.112
## 22:52:48 Read 2638 rows and found 10 numeric columns
## 22:52:48 Using Annoy for neighbor search, n_neighbors = 30
## 22:52:48 Building Annoy index with metric = cosine, n_trees = 50
## 0% 10 20 30 40 50 60 70 80 90 100%
## [----|----|----|----|----|----|----|----|----|----|
## **************************************************|
## 22:52:48 Writing NN index file to temp file C:\Users\lda\AppData\Local\Temp\Rtmp8CGyov\file5f84f137628
## 22:52:48 Searching Annoy index using 1 thread, search_k = 3000
## 22:52:49 Annoy recall = 100%
## 22:52:49 Commencing smooth kNN distance calibration using 1 thread
## 22:52:50 Initializing from normalized Laplacian + noise
## 22:52:50 Commencing optimization for 500 epochs, with 105124 positive edges
## 22:52:57 Optimization finished
1 | pbmc <- RunTSNE(pbmc, dims = 1:10) |
1 | # note that you can set `label = TRUE` or use the LabelClusters function to help label |
1 | DimPlot(pbmc, reduction = "tsne", label = TRUE) |
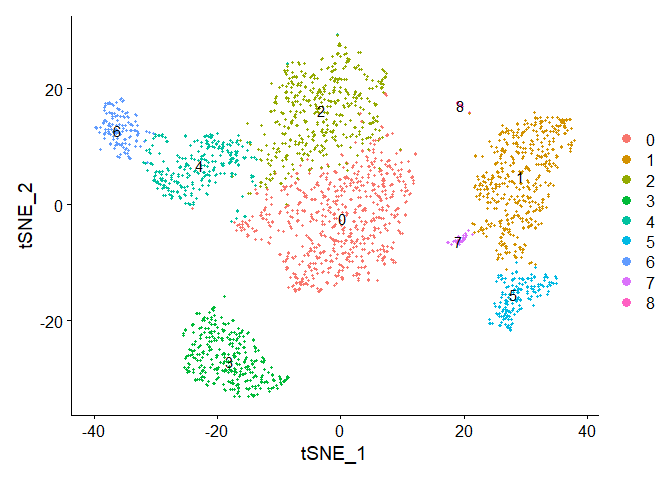
UMAP和tSNE的降维效果不同,需要根据实际情况选择。
在这里可以保存中间数据,作为一个checkpoint
1 | saveRDS(pbmc, file = "data/pbmc_tutorial.rds") |
鉴定差异表达特征(cluster markers)
Seurat支持对cluster之间进行差异表达分析,主要有 FindMarkers 和 FindAllMarkers 两种方法。
这里鉴定cluster 5和cluster 0, 3之间的差异基因。如果不指定 ident.2 则鉴定cluster 5 与其余clusters的差异基因。
min.pct 指定差异基因需要在cluster中的表达占比
1 | # find all markers distinguishing cluster 5 from clusters 0 and 3 |
## p_val avg_log2FC pct.1 pct.2 p_val_adj
## FCGR3A 2.150929e-209 4.267579 0.975 0.039 2.949784e-205
## IFITM3 6.103366e-199 3.877105 0.975 0.048 8.370156e-195
## CFD 8.891428e-198 3.411039 0.938 0.037 1.219370e-193
## CD68 2.374425e-194 3.014535 0.926 0.035 3.256286e-190
## RP11-290F20.3 9.308287e-191 2.722684 0.840 0.016 1.276538e-186
FindAllMarkers 可以一次寻找所有clusters的markers,但只返回上调的markers
1 | # find markers for every cluster compared to all remaining cells, report only the positive |
## Calculating cluster 0
## Calculating cluster 1
## Calculating cluster 2
## Calculating cluster 3
## Calculating cluster 4
## Calculating cluster 5
## Calculating cluster 6
## Calculating cluster 7
## Calculating cluster 8
1 | pbmc.markers %>% |
## Registered S3 method overwritten by 'cli':
## method from
## print.boxx spatstat.geom
## # A tibble: 18 x 7
## # Groups: cluster [9]
## p_val avg_log2FC pct.1 pct.2 p_val_adj cluster gene
## <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <chr>
## 1 1.17e- 83 1.33 0.435 0.108 1.60e- 79 0 CCR7
## 2 1.74e-109 1.07 0.897 0.593 2.39e-105 0 LDHB
## 3 0. 5.57 0.996 0.215 0. 1 S100A9
## 4 0. 5.48 0.975 0.121 0. 1 S100A8
## 5 7.99e- 87 1.28 0.981 0.644 1.10e- 82 2 LTB
## 6 2.61e- 59 1.24 0.424 0.111 3.58e- 55 2 AQP3
## 7 0. 4.31 0.936 0.041 0. 3 CD79A
## 8 9.48e-271 3.59 0.622 0.022 1.30e-266 3 TCL1A
## 9 4.93e-169 3.01 0.595 0.056 6.76e-165 4 GZMK
## 10 1.17e-178 2.97 0.957 0.241 1.60e-174 4 CCL5
## 11 3.51e-184 3.31 0.975 0.134 4.82e-180 5 FCGR3A
## 12 2.03e-125 3.09 1 0.315 2.78e-121 5 LST1
## 13 6.82e-175 4.92 0.958 0.135 9.36e-171 6 GNLY
## 14 1.05e-265 4.89 0.986 0.071 1.44e-261 6 GZMB
## 15 1.48e-220 3.87 0.812 0.011 2.03e-216 7 FCER1A
## 16 1.67e- 21 2.87 1 0.513 2.28e- 17 7 HLA-DPB1
## 17 3.68e-110 8.58 1 0.024 5.05e-106 8 PPBP
## 18 7.73e-200 7.24 1 0.01 1.06e-195 8 PF4
Visualization
Seurat提供多种基因表达量可视化方法
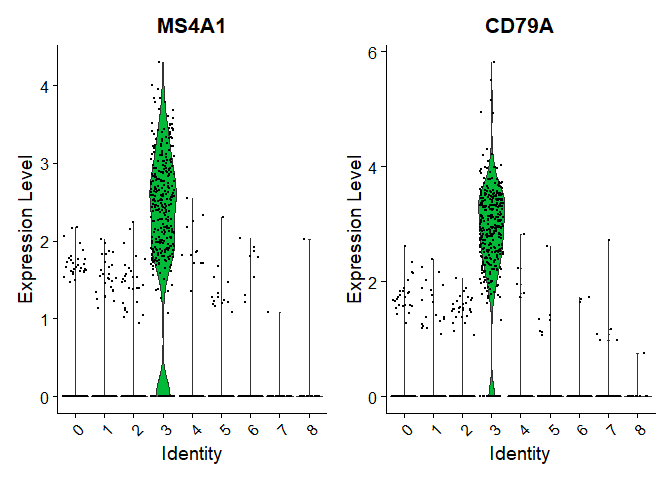
- 小提琴图
1 | VlnPlot(pbmc, features = c("MS4A1", "CD79A")) |
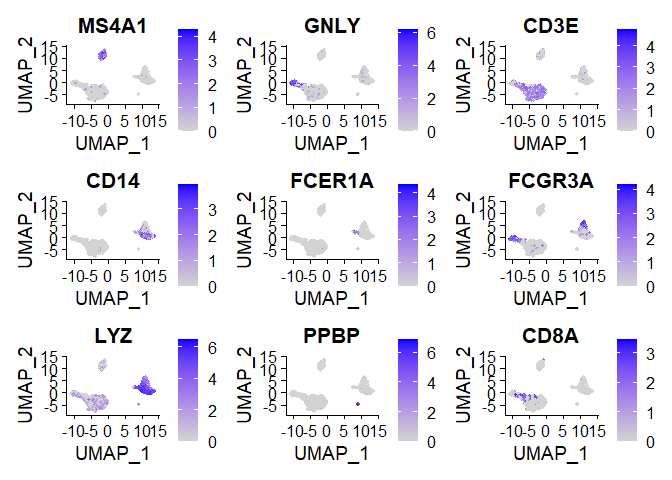
- 细胞降维图
1 | FeaturePlot(pbmc, features = c("MS4A1", "GNLY", "CD3E", "CD14", "FCER1A", "FCGR3A", "LYZ", "PPBP", |
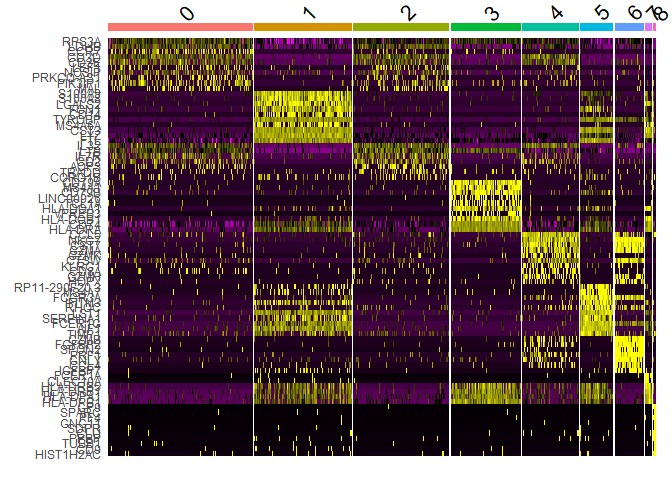
- 热图
1 | pbmc.markers %>% |
细胞注释
我们可以根据细胞marker基因的表达对细胞进行注释。虽然目前有一些自动注释的工具,但总的来说大家还是根据细胞的经典markers对细胞进行注释。
这里,我们根据教程中提供的cluster markers和细胞类型进行注释
Cluster ID Markers Cell Type
0 IL7R, CCR7 Naive CD4+ T
1 CD14, LYZ CD14+ Mono
2 IL7R, S100A4 Memory CD4+
3 MS4A1 B
4 CD8A CD8+ T
5 FCGR3A, MS4A7 FCGR3A+ Mono
6 GNLY, NKG7 NK
7 FCER1A, CST3 DC
8 PPBP Platelet
1 | new.cluster.ids <- c("Naive CD4 T", "CD14+ Mono", "Memory CD4 T", "B", "CD8 T", "FCGR3A+ Mono", |
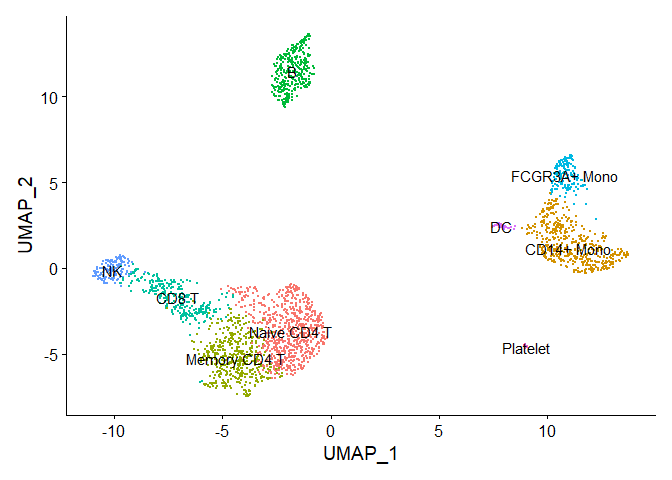
1 | saveRDS(pbmc, file = "data/pbmc3k_final.rds") |
至此,Seurat分析的常规流程就结束了。
Ref:
Seurat - Guided Clustering Tutorial: https://satijalab.org/seurat/articles/pbmc3k_tutorial.html