文章接受,终于有空再发点笔记了😃
SCENIC_Tutorial
Setup
1 | # http://htmlpreview.github.io/?https://github.com/aertslab/SCENIC/blob/master/inst/doc/SCENIC_Setup.html |
1 | #if (!dir.exists("SCENIC_MouseBrain/")) dir.create("SCENIC_MouseBrain/") |
下载相应转录因子数据库,本文用的数据来自小鼠,所以下载小鼠的数据库
由于直接从R这里下载的话会下载不完整,所以这里使用 zsync_curl 下载数据库。
ubuntu下zsync_curl安装可以参考: https://github.com/AppImage/zsync-curl
相应数据库的下载方式:https://resources.aertslab.org/cistarget/help.html
以下为shell命令行
1 |
|
下载后,将数据库置于当前工作目录的 cisTarget_databases/
其他的db和相关注释文件可从该网址下载https://resources.aertslab.org/cistarget/
Load Packages
1 | library(SCopeLoomR) |
Input
Expression matrix
这里使用官方提供的小鼠大脑的单细胞表达矩阵(862 genes * 200 cells)进行演示.
1 | loomPath <- system.file(package="SCENIC", "examples/mouseBrain_toy.loom") |
## [1] 862 200
Cell info/phenodata
1 | head(cellInfo) |
## CellType nGene nUMI
## 1772066100_D04 interneurons 170 509
## 1772063062_G01 oligodendrocytes 152 443
## 1772060224_F07 microglia 218 737
## 1772071035_G09 pyramidal CA1 265 1068
## 1772067066_E12 oligodendrocytes 81 273
## 1772066100_B01 pyramidal CA1 108 191
Numbers of different celltypes
1 | table(cellInfo$CellType) |
##
## astrocytes_ependymal interneurons microglia
## 29 43 14
## oligodendrocytes pyramidal CA1
## 55 59
save cell information
1 | saveRDS(cellInfo, file="int/cellInfo.Rds") |
设置每个celltype的颜色
1 | # Color to assign to the variables (same format as for NMF::aheatmap) |

Initialize SCENIC settings
在开始分析前,我们先初始化SCENIC分析的一些参数
1 | org <- "mgi" # or hgnc, or dmel |
为了演示,我们只分析10kb的数据库
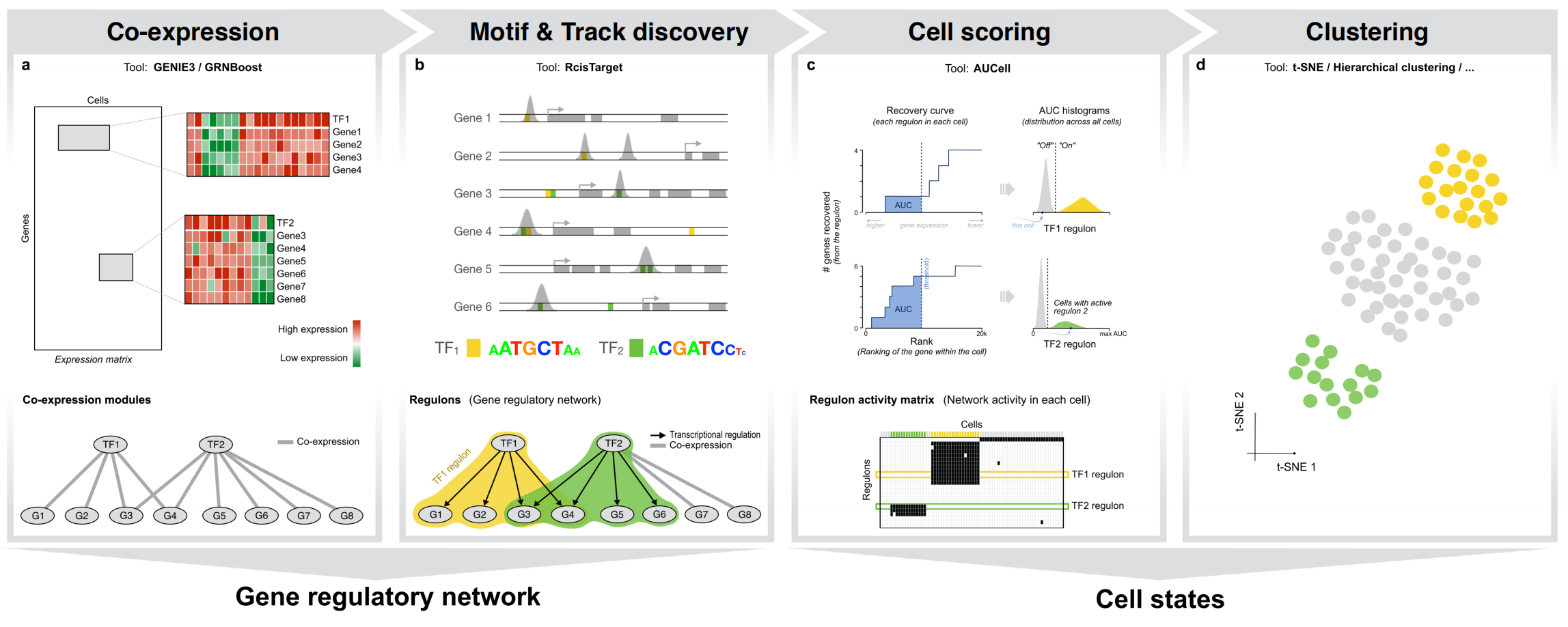
Co-expression network
SCENIC流程的第一步是基于表达数据推断潜在的转录因子靶标。这可以通过GENIE3或GRNBoost完成
这里我们需要输入的是:
- 过滤后的单细胞表达矩阵
- TF的列表(潜在的调控因子)
这一步完成后将会输出一个相关性矩阵,以生成基因共表达模块
Gene filter/selection
运行GENIE3/GRNBoost之前需要先对表达矩阵进行过滤,过滤的条件包括:
- 按每个基因的所有read counts过滤,以排除极低reads的测序噪声;
- 按检测到基因的细胞数过滤;
- 只保留在RcisTarget数据库中的基因进行分析。
1 | # (Adjust minimum values according to your dataset) |
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0 17.0 48.0 146.8 137.0 5868.0
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 10.00 25.00 39.01 60.00 180.00
需要注意的是过滤的条件需要根据数据集进行相应调整。
应用以上条件过滤,最终过滤后的表达矩阵为: 770 genes * 200 cells
1 | exprMat_filtered <- exprMat[genesKept, ] |
## [1] 770 200
Correlation
计算TF和其靶标的Spearman correlation。这一步会在 int/ 文件夹下生成 corrMat.Rds
1 | runCorrelation(exprMat_filtered, scenicOptions) |
## [1] "1.2_corrMat.Rds"
GENIE3
GENIE3是一种基于随机森林的算法,每次运行的结果都有些许差别,可以通过 set.seed 设置固定的种子以获得可重复的结果。
GENIE3使用转录因子的表达量作为变量预测每个靶基因的表达量,最后把训练输出模型的权重作为转录因子-靶基因的调控强度。
1 | # Optional: add log (if it is not logged/normalized already) |
Build and score the GRN
GENIE3/GRNBoost 完成后,就可以使用SCENIC推断基因调控网路(Gene Regulatory Network, GRN).
SCENIC的流程包括:
- 获取基因共表达模块
- 获取调控子 (with RcisTarget)
- 对每个细胞的GRN进行打分 (with AUCell)
- 根据GRN的活性对细胞进行聚类
1 | loom <- open_loom(loomPath) |
## [1] 862 200
运行SCENIC
runSCENIC_1_coexNetwork2modules: 将GENIE3/GRNBoost的结果转换为共表达模块runSCENIC_2_createRegulons: 调用RcisTarget,保留通过TF-motif富集分析后的共表达模块runSCENIC_3_scoreCells: 调用AUCell在每个细胞中对regulon进行打分,分数作为regulon在该细胞的活性
1 | scenicOptions <- runSCENIC_1_coexNetwork2modules(scenicOptions) |
## [,1]
## nTFs 8
## nTargets 770
## nGeneSets 47
## nLinks 17308
1 | scenicOptions <- runSCENIC_2_createRegulons(scenicOptions, coexMethod=c("top5perTarget")) #** Only for toy run!! |
## [,1]
## top5perTarget 8
## [1] 22058
1 | scenicOptions@settings$nCores <- 1 # for runSCENIC_3_scoreCells |
## min 1% 5% 10% 50% 100%
## 46.00 58.99 77.00 84.80 154.00 342.00
1 | saveRDS(scenicOptions, file="int/scenicOptions.Rds") # To save status |
上述每一步都会在int/中生成若干文件。
runSCENIC_1_coexNetwork2modules 计算了TF与每个基因的相关性权重,为了避免in-direct TF-target pairs的干扰,作者使用了几种过滤方法的组合来形成共表达基因模块(Modules)
方法 含义
w0.001 以TF为单位,保留weight > 0.01的基因形成modules
w0.005 以TF为单位,保留weight > 0.05的基因形成modules
top50 保留每个TF中weight top 50的基因
top5perTarget 以基因为单位,保留weight top 5的TF得到简化的TF-target pairs list,然后把基因分配给TF构建共表达模块
top10perTarget 以基因为单位,保留weight top 10的TF得到简化的TF-target pairs list,然后把基因分配给TF构建共表达模块
top50perTarget 以基因为单位,保留weight top 50的TF得到简化的TF-target pairs list,然后把基因分配给TF构建共表达模块
top1sd 保留每个TF中,weight大于 mean(weight) + sd(weight)的targets
top3sd 保留每个TF中,weight大于 mean(weight) + 3*sd(weight)的targets
runSCENIC_3_scoreCells使用AUCell计算每个regulon的活性
AUCell calculates the enrichment of the regulon as an area under the recovery curve (AUC) across the ranking of all genes in a particular cell, whereby genes are ranked by their expression value.
In brief, the scoring method is based on a recovery analysis where the x-axis (Supplementary Fig. 1c) is the ranking of all genes based on expression level (genes with the same expression value, e.g., ‘0’, are randomly sorted); and the y-axis is the number of genes recovered from the input set.
AUCell then uses the AUC to calculate whether a critical subset of the input gene set is enriched at the top of the ranking for each cell. In this way, the AUC represents the proportion of expressed genes in the signature and their relative expression values compared to the other genes within the cell.
get regulon activity matrix
runSCENIC_3_scoreCells将regulon打分的结果保存到’int/3.4_regulonAUC.Rds’中,我们可以读入这个数据进行分析。
1 | regulonAUC <- readRDS('int/3.4_regulonAUC.Rds') |
## [1] 7 200
## cells
## gene sets 1772066100_D04 1772063062_G01 1772060224_F07
## Tef (405g) 0.595558153 0.46756283 0.275862069
## Dlx5 (35g) 0.097560976 0.00000000 0.009059233
## Irf1 (105g) 0.000000000 0.05610754 0.382817066
## Stat6 (27g) 0.000000000 0.01399177 0.146502058
## Sox9 (150g) 0.210987726 0.22676797 0.049678551
## Sox10 (88g) 0.003506721 0.31092928 0.023962595
## Sox8 (98g) 0.042080655 0.26241964 0.026300409
这里我们获得了7个regulon在200个细胞中的打分矩阵,其中每一行是一个regulon,每一列是一个细胞。以”Tef (405g)”为例,该regulon id表示的意思是转录因子Tef这个模块当前调控405个潜在的靶基因。
Optional steps
在获取调控模块(regulons)X 细胞(cells)的AUC矩阵后,SCENIC的主要分析已经完成了,后续可以根据个人需求进一步分析。例如以下的这些分析。
二值化网络活性(regulon on/off)
这一步可以手动查看每一个regulon的binarized threshold是否合理,AUCell自动判断的阈值有时候会过于严格,以致某一regulon在所有细胞都被判断为off的状态。
1 | aucellApp <- plotTsne_AUCellApp(scenicOptions, exprMat_log) |
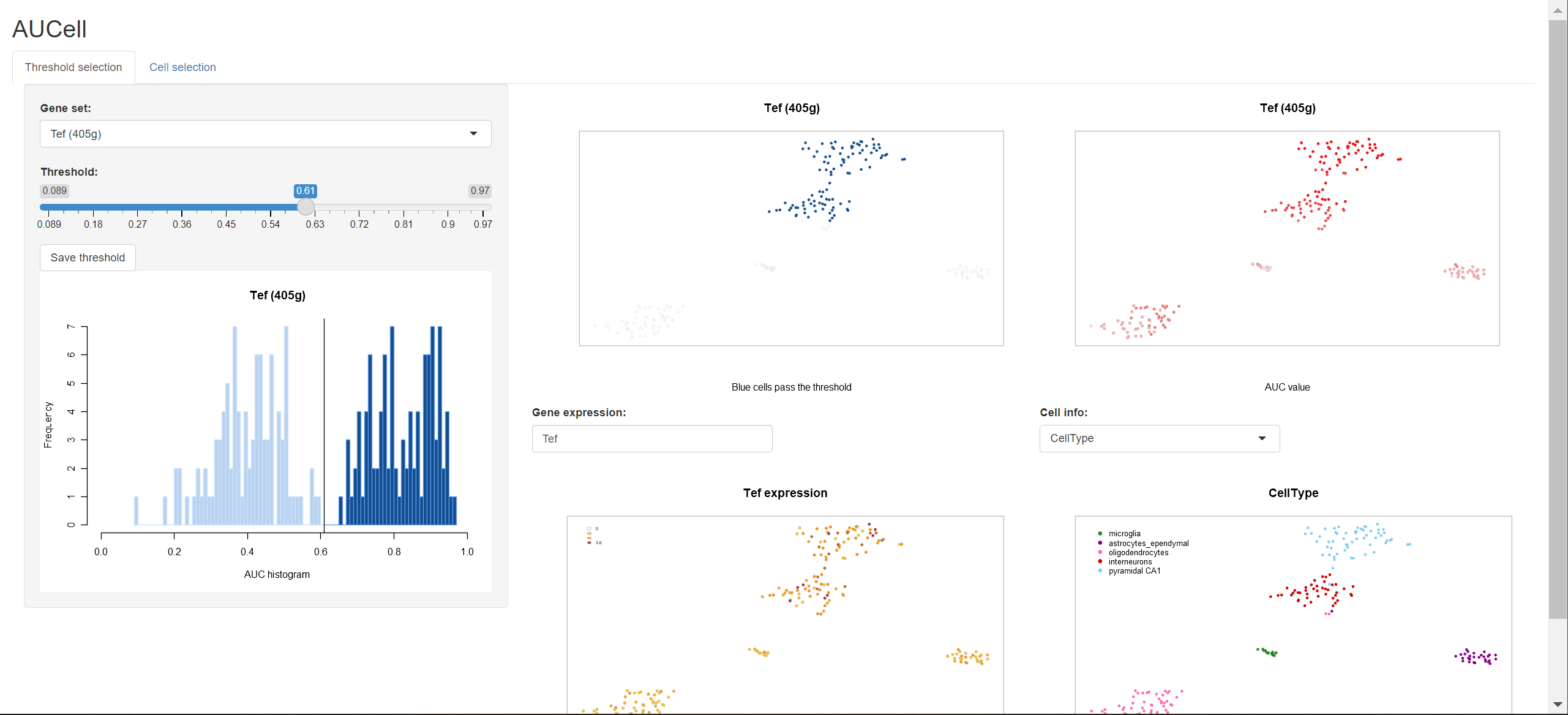
这一步会创建一个shinyapp,以探索定义基因模块激活的阈值。
1 | # Save the modified thresholds: |
二值化AUC
1 | scenicOptions <- runSCENIC_4_aucell_binarize(scenicOptions) |
基于调控活性的聚类与降维
我们可以根据调控模块的活性对细胞进行聚类。
1 | nPcs <- c(5) |
1 | par(mfrow=c(length(nPcs), 3)) |
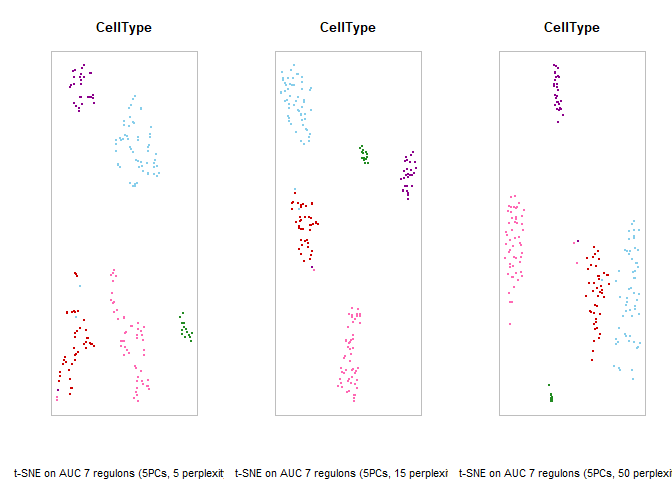

保存tSNE的参数
1 | scenicOptions@settings$defaultTsne$aucType <- "AUC" |
Exploring/interpreting the results
SCENIC 分析的结果在当前工作目录下的 output/ 中。
将AUC和TF的表达投影到tSNE
1 | tSNE_scenic <- readRDS(tsneFileName(scenicOptions)) |
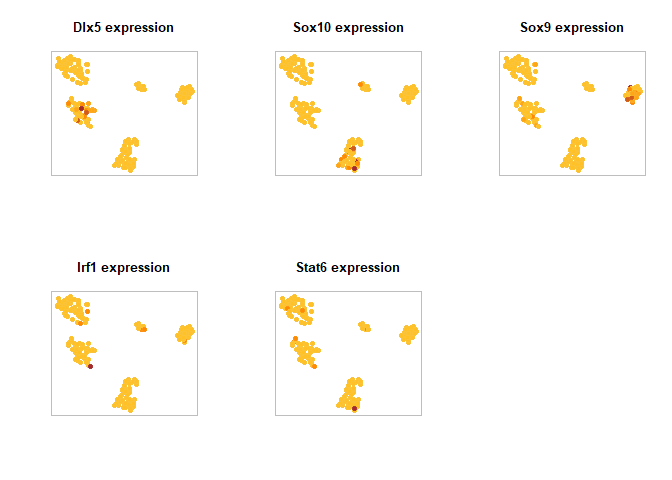
1 | # Save AUC as PDF: |
## png
## 2
以密度图的方式展示tSNE
1 | library(KernSmooth) |

展示多个调控子
这里注意原教程写于2020,用的是
SCENIC_1.2.0。到了2022年,SCENIC已经更新到1.3.1.,而plotTsne_rgb已经被替换为plotEmb_rgb
1 | #par(bg = "black") |
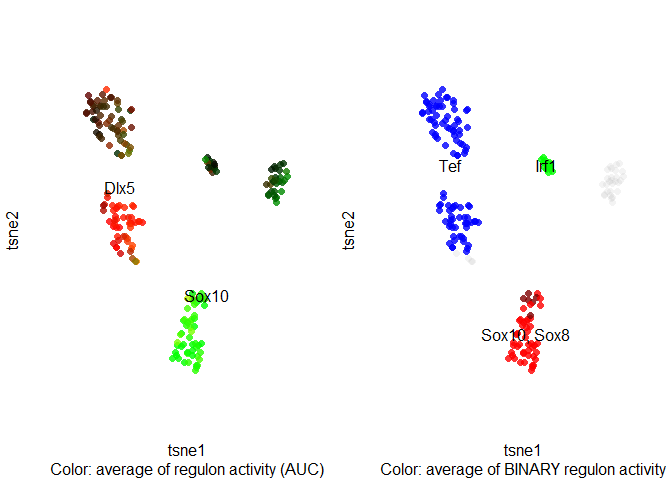
GRN: Regulon targets and motifs
列出当前基因调控网路中某个调控模块下的基因:
1 | regulons <- loadInt(scenicOptions, "regulons") |
## $Dlx5
## [1] "2610203C20Rik" "Adamts17" "AI854703" "Arhgef10l"
## [5] "Bahcc1" "Cirbp" "Cplx1" "Dlx1"
## [9] "Gad1" "Gadd45gip1" "Hexim2" "Igf1"
## [13] "Iglon5" "Ltbp3" "Myt1" "Npas1"
## [17] "Nxph1" "Peli2" "Plekha6" "Prkab1"
## [21] "Ptchd2" "Racgap1" "Rgs8" "Robo1"
## [25] "Rpl34" "Sema3c" "Shisa9" "Slc12a5"
## [29] "Slc39a6" "Spns2" "Stox2" "Syt6"
## [33] "Unc5d" "Wnt5a"
##
## $Irf1
## [1] "4930523C07Rik" "Acsl5" "Adrb1" "Ahdc1"
## [5] "Ahnak" "Akap1" "Anxa2" "Arhgap31"
## [9] "Arhgef10l" "Arhgef19" "Atg14" "B2m"
## [13] "Bank1" "Bcl2a1b" "Cald1" "Capsl"
## [17] "Ccl2" "Ccl3" "Ccl7" "Ccnd1"
## [21] "Ccnd3" "Cd163" "Cd48" "Cited2"
## [25] "Cmtm6" "Ctgf" "Ctnnd1" "Ctss"
## [29] "Ddr2" "E130114P18Rik" "Egfr" "Ehd1"
## [33] "Esam" "Fcer1g" "Fcgr1" "Fgf14"
## [37] "Fstl4" "Fyb" "Gabrb1" "Gadd45g"
## [41] "Gja1" "Gpr34" "Gramd3" "H2-K1"
## [45] "Hfe" "Il6ra" "Irf1" "Itgb5"
## [49] "Kcne4" "Kcnj16" "Kcnj2" "Laptm5"
## [53] "Lhfp" "Lrp4" "Map3k5" "Mdk"
## [57] "Med13" "Midn" "Mr1" "Ms4a7"
## [61] "Msr1" "Myh9" "Nin" "Nptx1"
## [65] "Osbpl6" "P2ry13" "Parp12" "Peli2"
## [69] "Plcl2" "Plekha6" "Prkab1" "Rab3il1"
## [73] "Rgs5" "Rhobtb2" "Rnase4" "Sepp1"
## [77] "Sertad2" "Sgk3" "Slamf9" "Slc4a4"
## [81] "Slc7a7" "Slco5a1" "Slitrk2" "Soat1"
## [85] "Srgn" "St3gal6" "St5" "St8sia4"
## [89] "Stard8" "Stat6" "Stk17b" "Tapbp"
## [93] "Tbxas1" "Tgfa" "Tgfb3" "Tmem100"
## [97] "Tnfaip3" "Tnfaip8" "Trib1" "Trpm7"
## [101] "Txnip" "Usp2" "Vgll4" "Vps37b"
## [105] "Zfp36l2"
一个regulon可以对应多个靶标,而AUC则是在靶标大于10个的regulons中进行运算。
1 | regulons <- loadInt(scenicOptions, "aucell_regulons") |
## [,1]
## Tef "Tef (405g)"
## Dlx5 "Dlx5 (35g)"
## Sox9 "Sox9 (150g)"
## Sox8 "Sox8 (98g)"
## Sox10 "Sox10 (88g)"
## Irf1 "Irf1 (105g)"
TF-target详细的对应关系在 output/Step2_regulonTargetsInfo.tsv 中
1 | regulonTargetsInfo <- loadInt(scenicOptions, "regulonTargetsInfo") |
## TF gene highConfAnnot nMotifs bestMotif NES motifDb
## 1: Stat6 4930523C07Rik TRUE 14 tfdimers__MD00051 3.39 10kb
## 2: Stat6 Bcl2a1b TRUE 11 tfdimers__MD00051 3.39 10kb
## 3: Stat6 Ccl3 TRUE 8 tfdimers__MD00051 3.39 10kb
## 4: Stat6 Cd14 TRUE 14 tfdimers__MD00051 3.39 10kb
## 5: Stat6 Clec4a2 TRUE 1 tfdimers__MD00051 3.39 10kb
## 6: Stat6 Col27a1 TRUE 9 tfdimers__MD00051 3.39 10kb
## coexModule spearCor CoexWeight
## 1: top5perTarget 0.17259814 0.06908293
## 2: top5perTarget 0.08241394 0.15894490
## 3: top5perTarget 0.13977515 0.07461879
## 4: top5perTarget 0.07996444 0.15006861
## 5: top5perTarget 0.10529877 0.24615271
## 6: top5perTarget 0.17040821 0.18443827
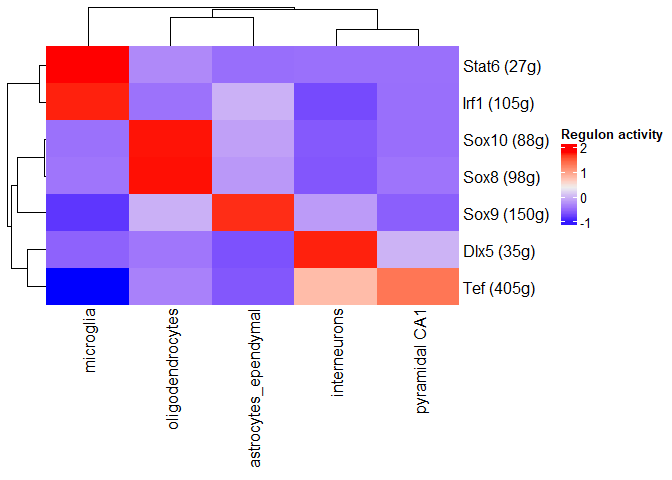
Regulators for known cell types or clusters
- 每个cluster的平均Regulon活性
1 | regulonAUC <- loadInt(scenicOptions, "aucell_regulonAUC") |
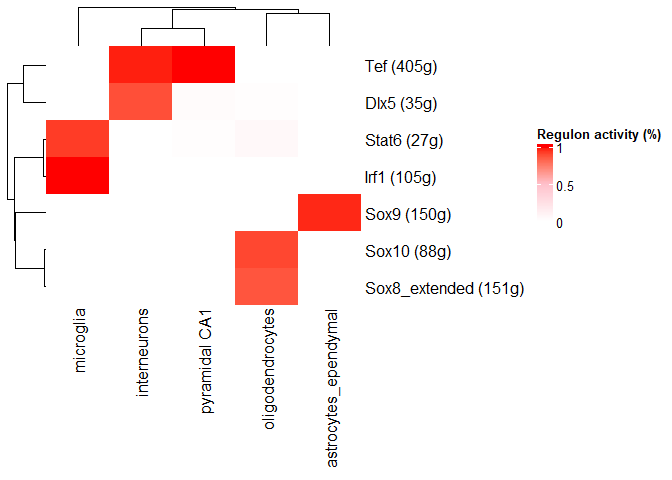
- 二值化版本(具有调节子活性的细胞类型/簇的细胞百分比)
1 | minPerc <- .7 |
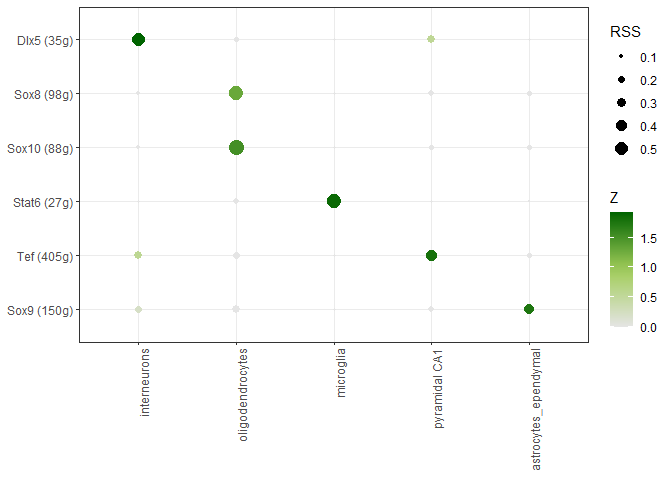
- 细胞特异性调控因子
我们还可以计算每个regulon在细胞中的特异性系数(Regulon Specificity Score, RSS)来衡量regulon在不同细胞类型间的特异程度。
RSS = 1-sqrt(JSD)
JSD: Jensen-Shannon Divergence
In probability theory and statistics, the Jensen–Shannon divergence is a method of measuring the similarity between two probability distributions.
https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence
1 | # regulonAUC <- loadInt(scenicOptions, "aucell_regulonAUC") |
以上就是SECENIC的分析流程,实际上计算AUC矩阵后就结束了,后续的分析都是根据课题需求进行的各种探索与可视化。
ref:
https://scenic.aertslab.org/tutorials/
https://github.com/aertslab/SCENIC/blob/master/R/runSCENIC_1_coexNetwork2modules.R