## 'SeuratObject' was built under R 4.4.0 but the current version is ## 4.4.1; it is recomended that you reinstall 'SeuratObject' as the ABI ## for R may have changed
## ## Attaching package: 'SeuratObject'
## The following objects are masked from 'package:base': ## ## intersect, t
library(ggplot2)
# Load the PBMC dataset pbmc.data <- Read10X(data.dir = "data/filtered_gene_bc_matrices/hg19/") # Initialize the Seurat object with the raw (non-normalized data). pbmc <- CreateSeuratObject(counts = pbmc.data, project = "pbmc3k", min.cells = 3, min.features = 200)
## Warning: Feature names cannot have underscores ('_'), replacing with dashes ## ('-')
pbmc
## An object of class Seurat ## 13714 features across 2700 samples within 1 assay ## Active assay: RNA (13714 features, 0 variable features) ## 1 layer present: counts
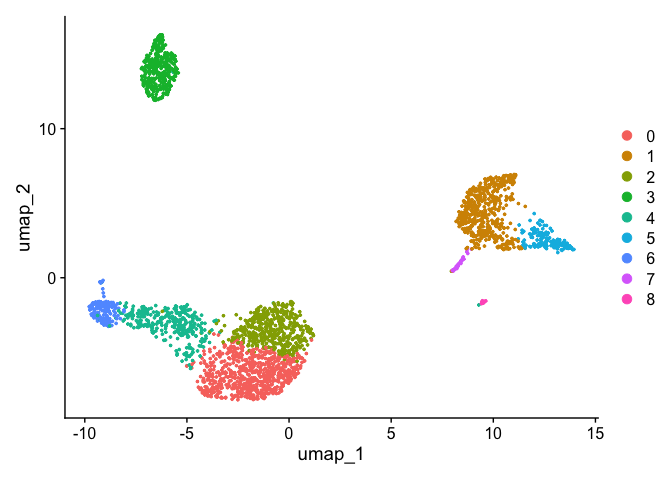
## Modularity Optimizer version 1.3.0 by Ludo Waltman and Nees Jan van Eck ## ## Number of nodes: 2700 ## Number of edges: 97892 ## ## Running Louvain algorithm... ## Maximum modularity in 10 random starts: 0.8719 ## Number of communities: 9 ## Elapsed time: 0 seconds
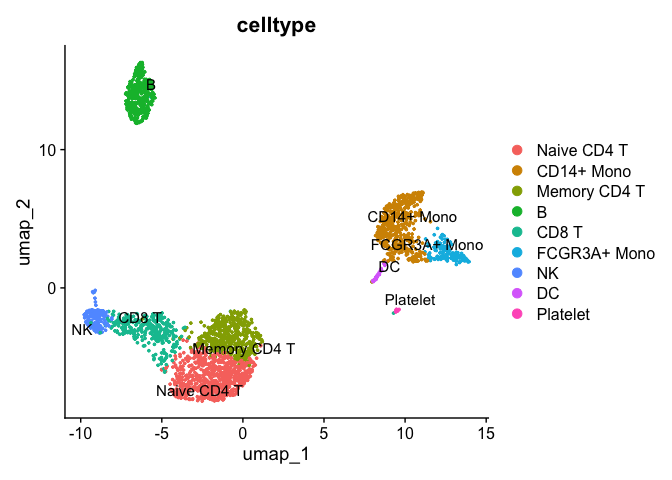
pbmc <- RunUMAP(object = pbmc, dims = 1:10)
## Warning: The default method for RunUMAP has changed from calling Python UMAP via reticulate to the R-native UWOT using the cosine metric ## To use Python UMAP via reticulate, set umap.method to 'umap-learn' and metric to 'correlation' ## This message will be shown once per session
## 11:53:34 UMAP embedding parameters a = 0.9922 b = 1.112
## 11:53:34 Read 2700 rows and found 10 numeric columns
## 11:53:34 Using Annoy for neighbor search, n_neighbors = 30
## 11:53:34 Building Annoy index with metric = cosine, n_trees = 50
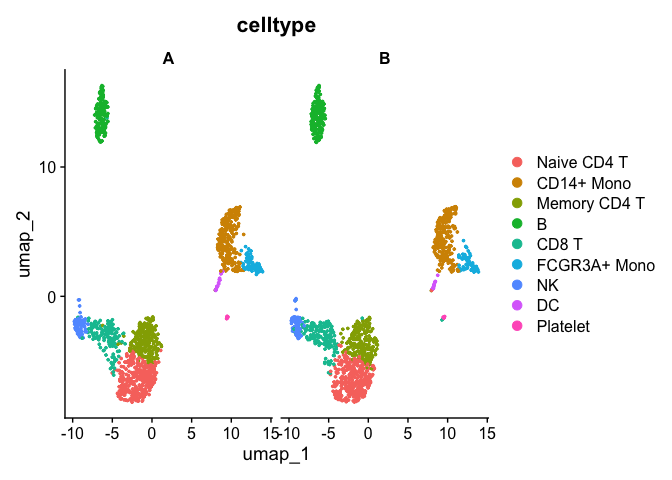
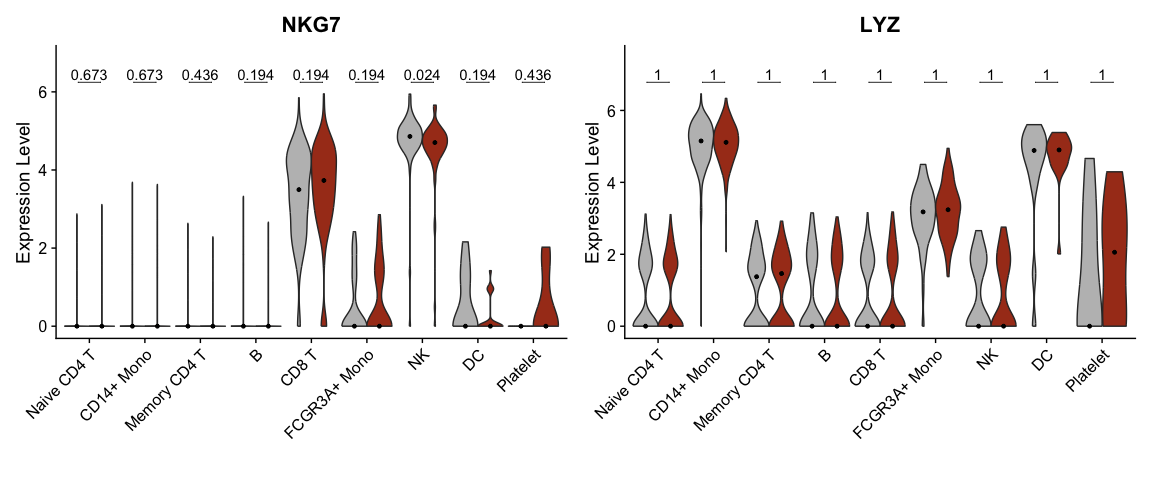
## The default behaviour of split.by has changed. ## Separate violin plots are now plotted side-by-side. ## To restore the old behaviour of a single split violin, ## set split.plot = TRUE. ## ## This message will be shown once per session.
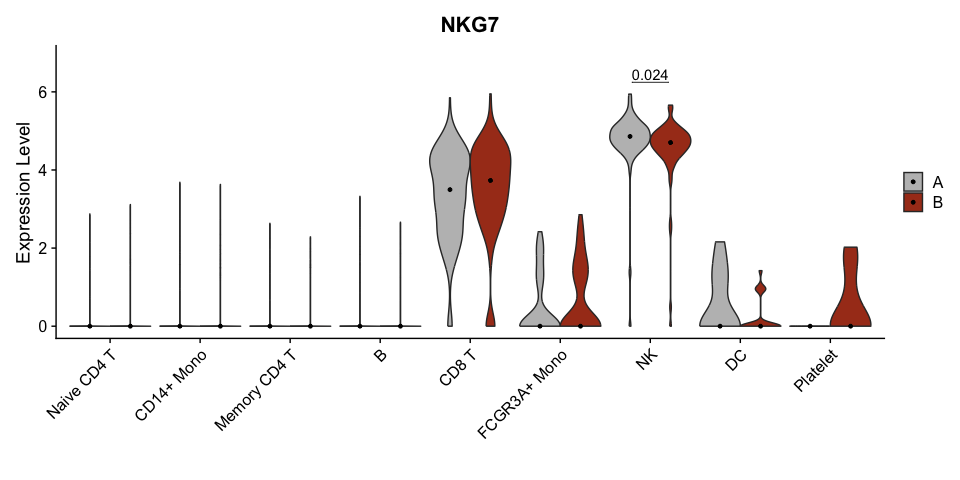
## Scale for y is already present. ## Adding another scale for y, which will replace the existing scale.
## Scale for y is already present. ## Adding another scale for y, which will replace the existing scale. ## Scale for y is already present. ## Adding another scale for y, which will replace the existing scale.