本文简单记录R包开发的流程
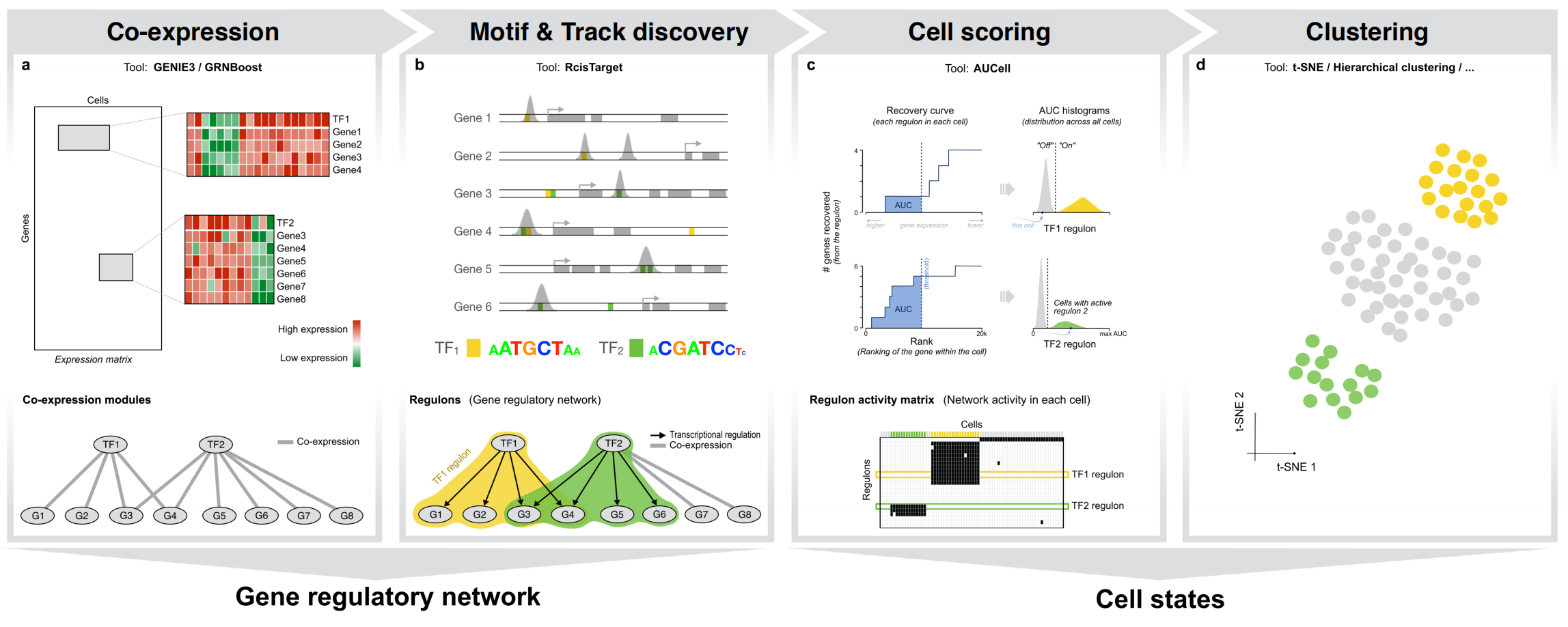
R-SCENIC
R-model-predict
conda-install-R-packages
R-ggplot调整分面宽度
R-Seurat数据分析流程
R-paintingr-调色板
“The greatest value of a picture is when it forces us to notice what we never expected to see.” - John Tukey
从油画当中汲取了一些配色方案,写成了一个R包 paintingr (https://github.com/thereallda/paintingr)
欢迎使用R画图的朋友给点意见和建议!
通路富集分析
Following tutorial from 2019 Nature Protocol (https://www.nature.com/articles/s41596-018-0103-9)

RNA-seq测序数据模拟
在评估不同软件性能的时候,我们会需要模拟一些数据。由于模拟数据当中的情况是已知的,例如差异表达基因的数目。因此,通过比较不同软件在模拟数据上的效果,我们可以获得软件的量化性能指标,例如灵敏度、特异性和准确度等。
本文根据 DESeq2 文章中的方法记录如何进行简单的基于负二项分布(Negative Binomial distribution)模拟RNA-seq基因表达数据。
R-获取基因长度
通常,在计算TPM或RPKM/FPKM等基因表达量时,除了基因的counts信息外,我们还需要知道基因的长度。这里所用到的基因长度并不是某个基因在基因组上的完整长度。在基因表达分析中,“基因长度”通常指的是成熟转录本的长度,也就是无内含子的碱基序列。因此,单纯地使用基因的染色体起始和结束坐标相减并不能返回转录本的长度信息。目前,对于基因长度有多种定义,包括:
1. 基因最长转录本;
2. 多个转录本长度的平均值;
3. 非重叠外显子长度之和
4. 非重叠CDS序列长度之和
本文介绍使用gtf文件在R中获取基因长度(非重叠外显子长度之和)的方法